Questo articolo riguarda l’utilizzo di tecniche di deep learning nella predizione del prezzo di un titolo di borsa. Questo è stato l’argomento della tesi di laurea magistrale di Vittorio Cecchetto: “Deep Learning per analisi del linguaggio naturale nell’ambito della predizione dei movimenti azionari”.
La predizione del prezzo di un titolo azionario, in ambito finanziario, può essere calcolata seguendo due diversi approcci. Il primo approccio, detto analisi fondamentale, si basa sulla solidità patrimoniale e la redditività di un’azienda per determinarne il valore intrinseco, attraverso una quantificazione del valore effettivo attuale e dei progetti futuri, allo scopo di stimarne la crescita o la decrescita.
Il secondo approccio, detto analisi tecnica, si basa invece sullo studio dell’andamento del prezzo del titolo nel tempo. Trascurando le informazioni relative all’azienda, l’unico dato di interesse è il prezzo del titolo, presumendo che nell’andamento del prezzo sia riassunta la storia, il presente e il futuro dell’azienda, almeno nel breve periodo.
L’analisi tecnica classica parte dal grafico dell’andamento di un titolo azionario e mediante indicatori, metodi matematici e statistici, ha l’obiettivo di individuare degli intervalli temporali in cui il prezzo del titolo è sopravvalutato o sottovalutato, in maniera tale da suggerire la vendita o l’acquisto delle azioni di quell’azienda. Negli ultimi anni l’analisi tecnica ha un nuovo alleato: l’intelligenza artificiale (AI). Le capacità predittive delle AI di ultima generazione sono infatti in grado di effettuare previsioni dell’andamento del titolo, non solo in determinati momenti nella storia, ma con continuità, avendo inoltre un grado di accuratezza molto elevato.
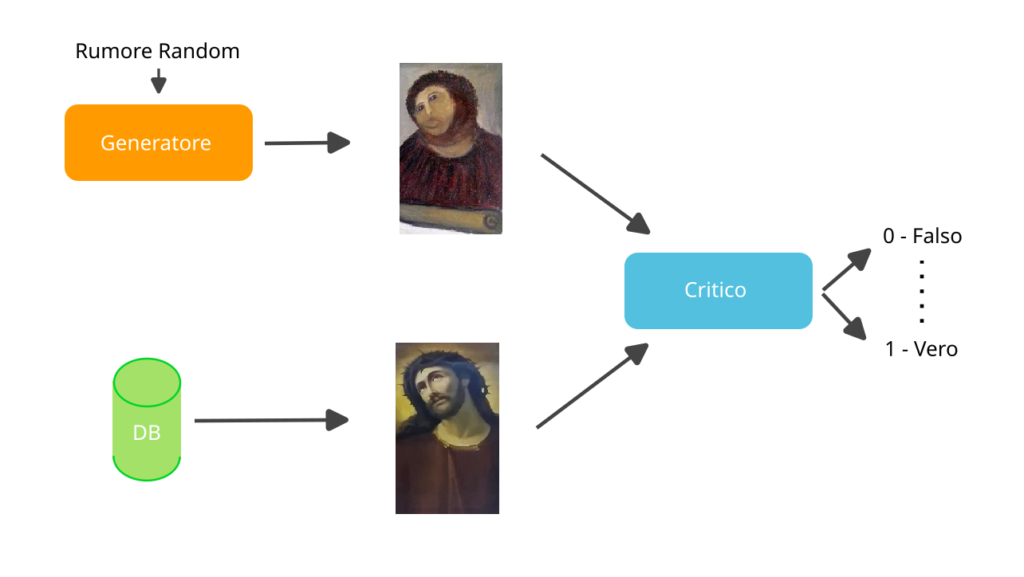
Uno dei modelli più recenti è stato proposto per la prima volta nel 2017 [1] e prende il nome di Wasserstein Generative Adversarial Network (WGAN). Per dare un’idea intuitiva del suo funzionamento (si veda la figura 1), supponiamo di avere un insieme di immagini di dipinti di un determinato pittore. Una WGAN contiene al suo interno due AI: una cerca di generare immagini simili ai dipinti del pittore; l’altra, invece, interpreta il ruolo del critico d’arte e deve stabilire se un’immagine che gli viene presentata sia in realtà un dipinto originale o un falso. Durante l’addestramento, la AI che genera i dipinti diventerà sempre più brava nell’imitare lo stile del pittore, mentre la AI che svolge il ruolo del critico diventerà sempre più in gamba nello smascherare i falsi.
Figura 1: principio di funzionamento di una Generative Adversarial Network (GAN)
Nella tesi di laurea è stata applicata una AI di tipo WGAN per predire l’andamento del prezzo di un titolo di borsa, quello della Apple. All’interno della WGAN, una AI aveva il compito di generare l’andamento del prezzo del giorno successivo a partire dalle informazioni relative ai tre giorni precedenti e la seconda AI aveva il compito di stabilire se il prezzo proposto dalla prima AI fosse verosimile o meno.
Per addestrare le reti neurali abbiamo utilizzato i dati dell’andamento del prezzo del titolo della Apple, presi su una finestra temporale di 10 anni. A questi sono stati aggiunti gli andamenti dei titoli di alcune aziende big-tech (Google, Facebook, Amazon, Microsoft), di alcune materie prime (Oro, Petrolio) e di alcuni indici azionari (S&P500, Nasdaq, Dow Jones, NYSE, FTSE100, Hang Seng, Nikkei, SSE, S&P BSE, Euro Stoxx 50, Euronext 100). A questi dati è stato aggiunto il Sentiment relativo ad alcune news finanziarie riguardanti la Apple. Le news sono state estrapolate da seekingalpha.com, un sito di notizie finanziarie, attraverso tecniche di web scraping. Alle news estratte è stato applicato un modello AI chiamato FinBERT, realizzato a partire da un modello denominato BERT creato dal team di Google, utilizzato per effettuare la Sentiment Analysis, ottenendo un indice che specifica se la notizia è positiva , negativa o neutrale per la Apple.
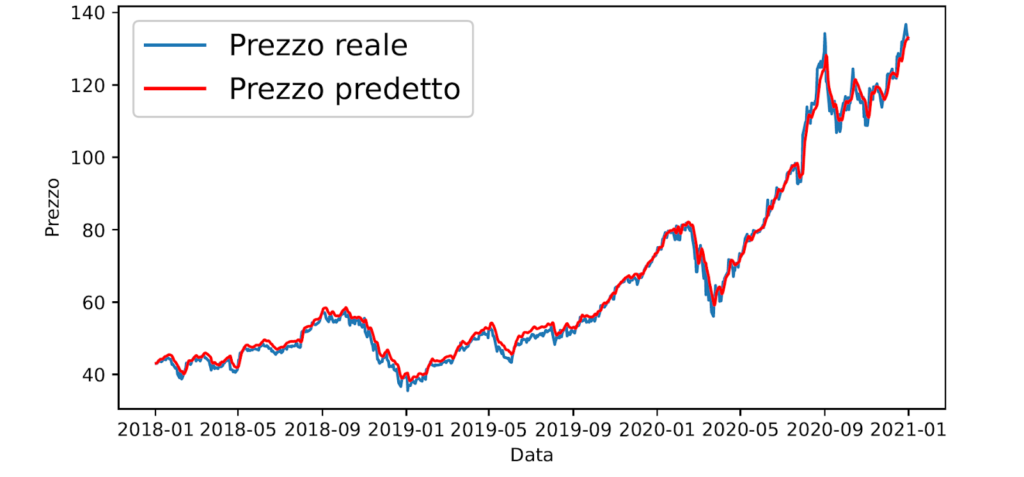
I dati sono stati utilizzati in parte per addestrare la AI (80%) e, finito l’addestramento, i rimanenti dati (20%) sono stati utilizzati per testare il comportamento della AI reale. I risultati ottenuti sono quelli visibili nella figura 2: il prezzo predetto è molto vicino al prezzo reale, con un errore quadratico medio di 2.05.
Figura 2: Confronto tra prezzo reale e prezzo predetto
I dati su cui è stato condotto l’addestramento possono sembrare molti, ma in realtà servirebbero quantità di dati molto maggiori: si può, ad esempio, immaginare di utilizzare questa tecnica nel mondo dell’High Frequency Trading, dove la quantità di dati a disposizione è di migliaia di volte superiore a quella qui utilizzata.
Riferimenti:
[1] M. Arjovsky, S. Chintala, L. Bottou, Wasserstein Generative Adversarial Networks, Proceedings of the 34th International Conference on Machine Learning, vol. 70, pag. 214-223 (2017).